|
Matcher Metadata
The MOMA-A Matcher Metadata captures information about existing ontology matchers.
For the classification of the algorithms we rely (in the first version) on the work of Rahm & Bernstein
who make the distinction between individual and combining matchers. |
Ontology Metadata The matcher inputs (i.e. ontologies) are described using the metadata model see "Using Context Information to Improve Ontology Reuse", pdf), which can be applied to describe ontologies in various phases of their life-cycle. Accounting for the fact that matching algorithms cannot be applied with the same success expectations regardless of any dimension of the ontology metadata model, we have identified the following ontology features as relevant for matching tasks:
|
|
Rules In order to automatically infer which
algorithms suit to certain inputs, it needs explicit knowledge regarding the
dependencies between these algorithms and the structures on which they
operate. We formalize this knowledge into dependency rulesstatements
that determine which elements (in this case which matchers) are to be used or excluded.
|
Selection Engine For a given pair of ontologies
to be matched, the MOMA selection engine has
to decide which matching algorithms should be applied to obtain the desired outputs. |
Metadata-based Ontology MAtching (MOMA) Framework
MOMA Framework
MOMA-A
The (automated) MOMA Framework (MOMA-A) allows a more flexible,
automatically triggered usage of various matching algorithms, depending
on their suitability to particular phases of the ontology management process.
Due to its generic and automatic character the approach can be applied in a
service-oriented context, in order to enable the discovery and operation of appropriate
matching services required to deal with specific, (previously unknown) ontologies.
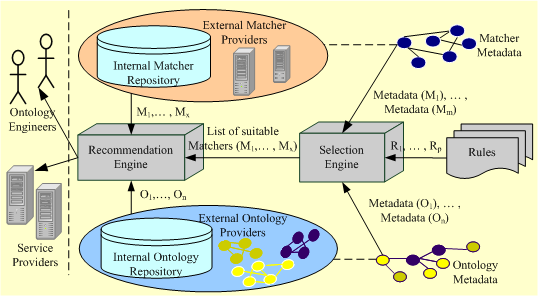 The MOMA-A Framework uses semantical descriptions of both single
matching algorithms and Web ontologies, which are then related by means of
rules to detect the suitable (with respect to the given ontologiecal input) matching approach.
The MOMA-A Framework uses semantical descriptions of both single
matching algorithms and Web ontologies, which are then related by means of
rules to detect the suitable (with respect to the given ontologiecal input) matching approach.
Our MOMA-A Framework consists of the following components (see MOMA-A Architecture):
- matcher repository (internal matcher repository + external matcher provider) with reusable matching components
- matcher metadata describes the properties of single matchers, e.g. information concerning the ontological formats served by particular matches, information regarding match results that can be delivered or the natural language that the algorithm can handle
- ontology repository manages the matching inputs defined by the ontology metadata
- ontology metadata describes the ontologies to be matched
- rule repository links ontology and matching properties and helps to determine which matching algorithms is to be used for which type of ontologies
- selection engine is responsible for the process of determination which algorithms are applicable to a specific set of inputs
MOMA-A Description Matcher Metadata Ontology Metadata Rules Selection Engine
MOMA-M Description
Further information MOMA Publications Contact
Related Links Ontology Matching OAEI 2006 OAEI 2005 MOMA from Leipzig
(A Mapping-based Object Matching System)
©2006 Freie Universität Berlin